
TL;DR
Use the reciprocal rank fusion algorithm to combine the results of BM25 and kNN semantic search.
Introduction
I’ve prepared a Jupyter notebook that demonstrates how to use the reciprocal rank fusion algorithm using Elastic.Clients.Elasticsearch. You can find the source code here.
Hybrid Search
In my previous blog posts, you have seen two different approaches to search a collection of documents (Semantic Search with Elasticsearch in .NET and Querying and Filtering via Elastic.Clients.Elasticsearch in .NET), each with its own particular benefits. If one of these methods matches your needs then you don’t need anything else, but in many cases each method of searching returns valuable results that the other method would miss, so the best option is to offer a combined result set.
For these cases, Elasticsearch offers Reciprocal Rank Fusion, an algorithm that combines results from two or more lists into a single list.
How RRF Works in Elasticsearch
☝️ RRF is based on the concept of reciprocal rank, which is the inverse of the rank of the first relevant document in a list of search results. The goal of the technique is to take into account the position of the items in the original rankings, and give higher importance to items that are ranked higher in multiple lists. This can help improve the overall quality and reliability of the final ranking, making it more useful for the task of fusing multiple ordered search results.
Elasticsearch integrates the RRF algorithm into the search query. Consider the following example, which has query and knn sections to request full-text and vector searches respectively, and a rrf section that combines them into a single result list.
{
"query":{
// full-text search query here
},
"knn":{
// vector search query here
},
"rank":{
"rrf": {}
}
}
While RRF works fairly well for short lists of results without any configuration, there are some parameters that can be tuned to provide the best results. Consult the documentation to learn about these in detail.
Demo
⚠️ I assume you already have the “book_index” dataset from my previous post Semantic Search with Elasticsearch in .NET. If you don’t, please follow the instructions in that post to set up the dataset.
1️⃣ First, let’s define a method to convert a search query to an embedding vector. I will use Microsoft.Extensions.AI. It requires Azure Open AI model to generate embeddings. I will go with (text-embedding-3-small) because it allows you to specify embedding size. This is important because the size of the embedding vector should match the size of the vector field in the Elasticsearch index and Elasticsearch has a limit of 512 dimensions for vector fields.
💡 Larger embeddings can capture more nuances and subtle relationships in the data, potentially leading to better model accuracy. However, very large embeddings can also lead to overfitting, where the model performs well on training data but poorly on unseen data. This is because the model might learn to memorize the training data rather than generalize from it.
Here is the code to generate an embedding vector for a given text:
using Azure.AI.OpenAI;
using Microsoft.Extensions.AI;
using System.ClientModel;
AzureOpenAIClient aiClient = new AzureOpenAIClient(
new Uri(envs["AZURE_OPENAI_ENDPOINT"]),
new ApiKeyCredential(envs["AZURE_OPENAI_APIKEY"]));
var generator = aiClient.AsEmbeddingGenerator(modelId: "text-embedding-3-small");
async Task<float[]> ToEmbedding(string text)
{
var textEmbeddingDimension = 384;
var embeddings = await generator.GenerateAsync([text], new EmbeddingGenerationOptions {
Dimensions = textEmbeddingDimension
});
return embeddings.First().Vector.ToArray();
}
2️⃣ Now we can use this method to generate an embedding vector for a search query and use it in both full-text and vector search queries.
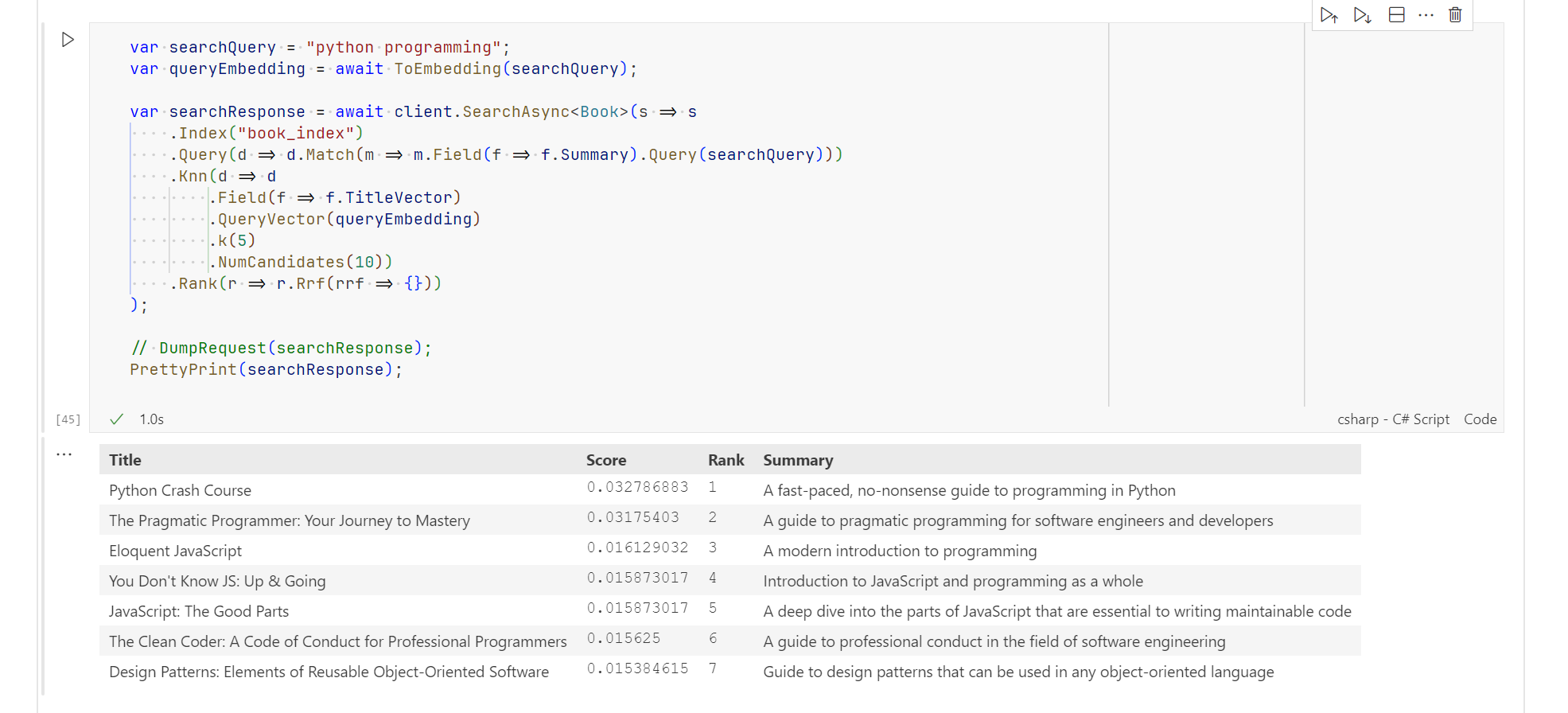
var searchQuery = "python programming";
var queryEmbedding = await ToEmbedding(searchQuery);
var searchResponse = await client.SearchAsync<Book>(s => s
.Index("book_index")
.Query(d => d.Match(m => m.Field(f => f.Summary).Query(searchQuery)))
.Knn(d => d
.Field(f => f.TitleVector)
.QueryVector(queryEmbedding)
.k(5)
.NumCandidates(10))
.Rank(r => r.Rrf(rrf => {}))
);
PrettyPrint(searchResponse);
Conclusion
🙌 I hope you found it helpful. If you have any questions, please feel free to reach out. If you’d like to support my work, a star on GitHub would be greatly appreciated! 🙏
References
- https://github.com/NikiforovAll/elasticsearch-dotnet-playground/tree/main/src/elasticsearch-getting-started
- https://github.com/NikiforovAll/elasticsearch-dotnet-playground/blob/main/src/elasticsearch-getting-started/02-hybrid-search.ipynb
- https://www.elastic.co/search-labs/tutorials/search-tutorial/welcome
- https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking
