
TL;DR
Source code: https://github.com/NikiforovAll/typical-rag-dotnet
Introduction
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing.
Kernel Memory works and scales best when running as a service (separate process), allowing the ingestion of thousands of documents and information without blocking your app However, you can also use the MemoryServerless class in your app, using KernelMemoryBuilder.
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"))
.Build<MemoryServerless>();
// Import a file
await memory.ImportDocumentAsync("meeting-transcript.docx", tags: new() { { "user", "Blake" } });
// Ask questions
var answer1 = await memory.AskAsync("How many people attended the meeting?");
The MemoryServerless class is a lightweight in-process version of the Kernel Memory service.
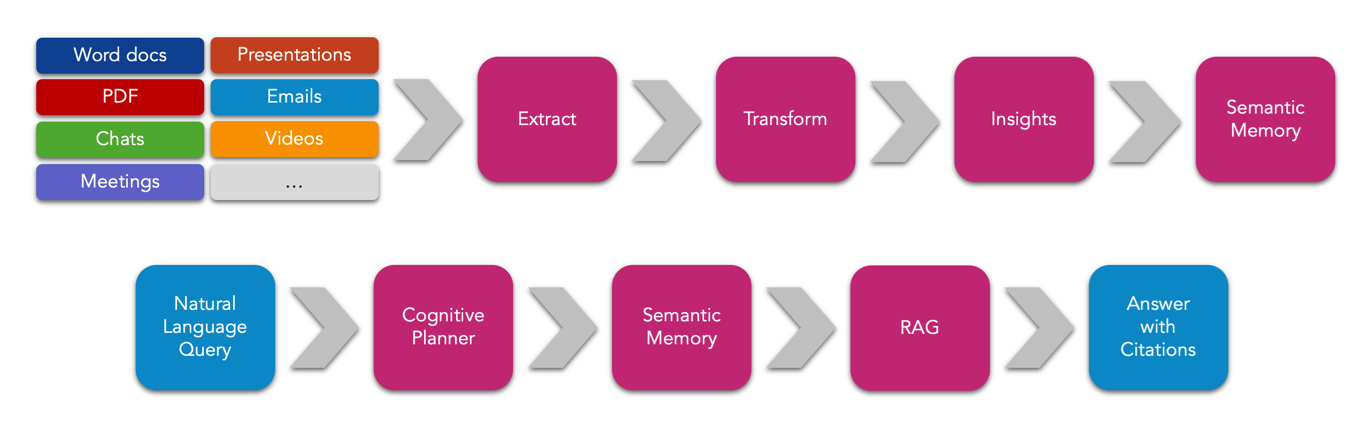
The Kernel Memory architecture can be divided in two main areas: Ingestion and Retrieval.
When a client sends a file, the service first saves data in the Content Storage, such as Azure Blobs or Local Disk. During this phase, a client stays connected, sending data and waiting for the data to be stored. Only when this operation is complete, Kernel Memory releases the client request and starts an asynchronous pipeline, to complete the ingestion without blocking the client.
Kernel Memory ingestion offers a default pipeline, composed by these sequential steps. Each step depends on the previous to complete successfully before starting. These steps are implemented by Handlers, shipped with the Core library. The list of steps and the logic of handlers can be customized. The default pipeline looks as follows:
- Text Extraction (e.g.: from PDF, DOCX, web page, etc.) (name:
extract) - Splitting text into partitions (name:
partition) - Generating embedding vectors for each partition (name:
gen_embeddings) - Store embedding vectors and metadata in a memory DB. (name:
save_records)
KM uses two types of storage:
- Content Storage: stores raw data uploaded by clients, pipeline status, unique IDs assigned to documents.
- Memory Storage: databases with search capability, where KM stores partitions and metadata (aka “memories”)
Kernel Memory is composable in two ways:
- Customizable components: you can choose a Vector Database, Content Storage, Embedding Generator, and Summarizer (LLM).
- Extensible pipeline: you can add custom handlers to the pipeline, or replace the default ones.
Now, let’s see how to build a typical RAG solution using Semantic Kernel, Kernel Memory, and Aspire in .NET.
Code
The awesome thing about Kernel Memory is that it provides an out-of-the-box solution. Microsoft.KernelMemory.Service.AspNetCore package provides a set of endpoints to interact with the service. You can use these endpoints to upload documents, ask questions, and get answers.
Basically, it boils down to the following:
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddKernelMemory<MemoryServerless>();
var app = builder.Build();
app.AddKernelMemoryEndpoints(apiPrefix: "/rag");
app.Run();
As a result, you will get the following endpoints:
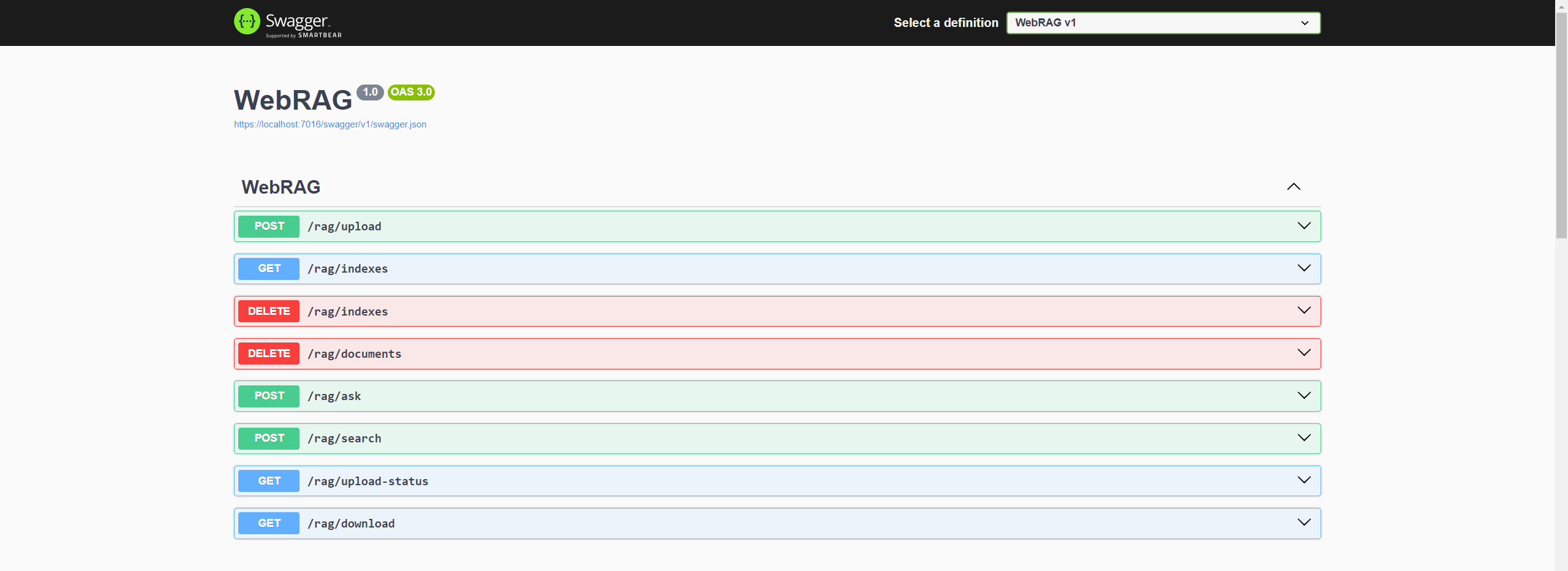
Let’s see how to actually make it work by adding essential components, such as LLM, Vector Database, and Content Storage.
Before we see how to configure Kernel Memory, let’s see how to configure Aspire.
Set up Aspire
We will use Postgres as a Vector and Content Database and we will use Azure Open AI to generate embeddings and summaries.
💡 Aspire comes with OpenTelemetry support. I strongly suggest adding observability to your RAG solutions from the beginning because you really want to know how everything works together and how long it takes to serve a response.
💡 Consider latency as part of your UI/UX since the retrieval and call to the LLM can significantly increase the response time.
// AppHost/Program.cs
var builder = DistributedApplication.CreateBuilder(args);
var db = builder
.AddPostgres("postgres", port: 5432)
.WithImage("pgvector/pgvector")
.WithImageTag("pg16")
.WithInitBindMount("resources/init-db")
.WithDataVolume()
.WithPgAdmin()
.AddDatabase("rag-db")
.WithHealthCheck();
var openai = builder.ExecutionContext.IsPublishMode
? builder
.AddAzureOpenAI("openai")
.AddDeployment(
new AzureOpenAIDeployment(
name: "gpt-4",
modelName: "gpt-4",
modelVersion: "2024-05-13",
skuName: "Standard",
skuCapacity: 1000
)
)
: builder.AddConnectionString("openai");
builder
.AddProject<Projects.WebRAG>("rag-web")
.WithReference(db)
.WithReference(openai)
.WaitFor(db);
builder.Build().Run();
Set up Kernel Memory
Now, when we have Aspire set up, let’s see how to configure Kernel Memory.
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.AddNpgsqlDataSource("rag-db"); // Adds OpenTelemetry and health checks for Postgres
builder.ConfigureAiOptions();
var aiOptions = builder.GetAiOptions();
builder.Services.AddKernelMemory<MemoryServerless>(memoryBuilder =>
{
memoryBuilder
.WithPostgresMemoryDb(
new PostgresConfig()
{
ConnectionString = builder.Configuration.GetConnectionString("rag-db")!
}
)
.WithSemanticKernelTextGenerationService(
new AzureOpenAIChatCompletionService(
deploymentName: aiOptions.Deployment,
endpoint: aiOptions.Endpoint,
apiKey: aiOptions.ApiKey
),
new SemanticKernelConfig()
)
.WithSemanticKernelTextEmbeddingGenerationService(
new AzureOpenAITextEmbeddingGenerationService(
deploymentName: "text-embedding-ada-002",
endpoint: aiOptions.Endpoint,
apiKey: aiOptions.ApiKey
),
new SemanticKernelConfig()
);
});
var app = builder.Build();
app.MapDefaultEndpoints();
app.AddKernelMemoryEndpoints(apiPrefix: "/rag");
app.Run();
IKernelMemoryBuilder provides a fluent API to configure Kernel Memory.
💡 We are using Azure OpenAI services through Semantic Kernel because it provides additional OpenTelemetry instrumentation. Later, we will see how it works in practice.
Demo
Let’s run the application and see how it works.
But before that, we need to configure the OpenAI connection string in AppHost/appsettings.json:
{
"ConnectionStrings": {
"OpenAI": "Endpoint=https://{account_name}.openai.azure.com/;Key={account_key};Deployment=gpt-4"
}
}
And run:
dotnet run --project src/AppHost/
Upload a Document
Now, let’s upload a document by calling the POST /rag/upload endpoint.
POST https://localhost:7016/rag/upload HTTP/1.1
accept: application/json
Content-Type: multipart/form-data; boundary=boundary
--boundary
Content-Disposition: form-data; name="file"; filename="AzureFundamentals.pdf"
Content-Type: pdf
< ./AzureFundamentals.pdf
--boundary--
Response:
{
"index": "",
"documentId": "20240903.124353.69a8ef269a0d43989c53719128054436",
"message": "Document upload completed, ingestion pipeline started"
}
It took about 1 minute to process the document. As you can see below, multiple calls were made to the OpenAI service to generate an embedding for each partition.
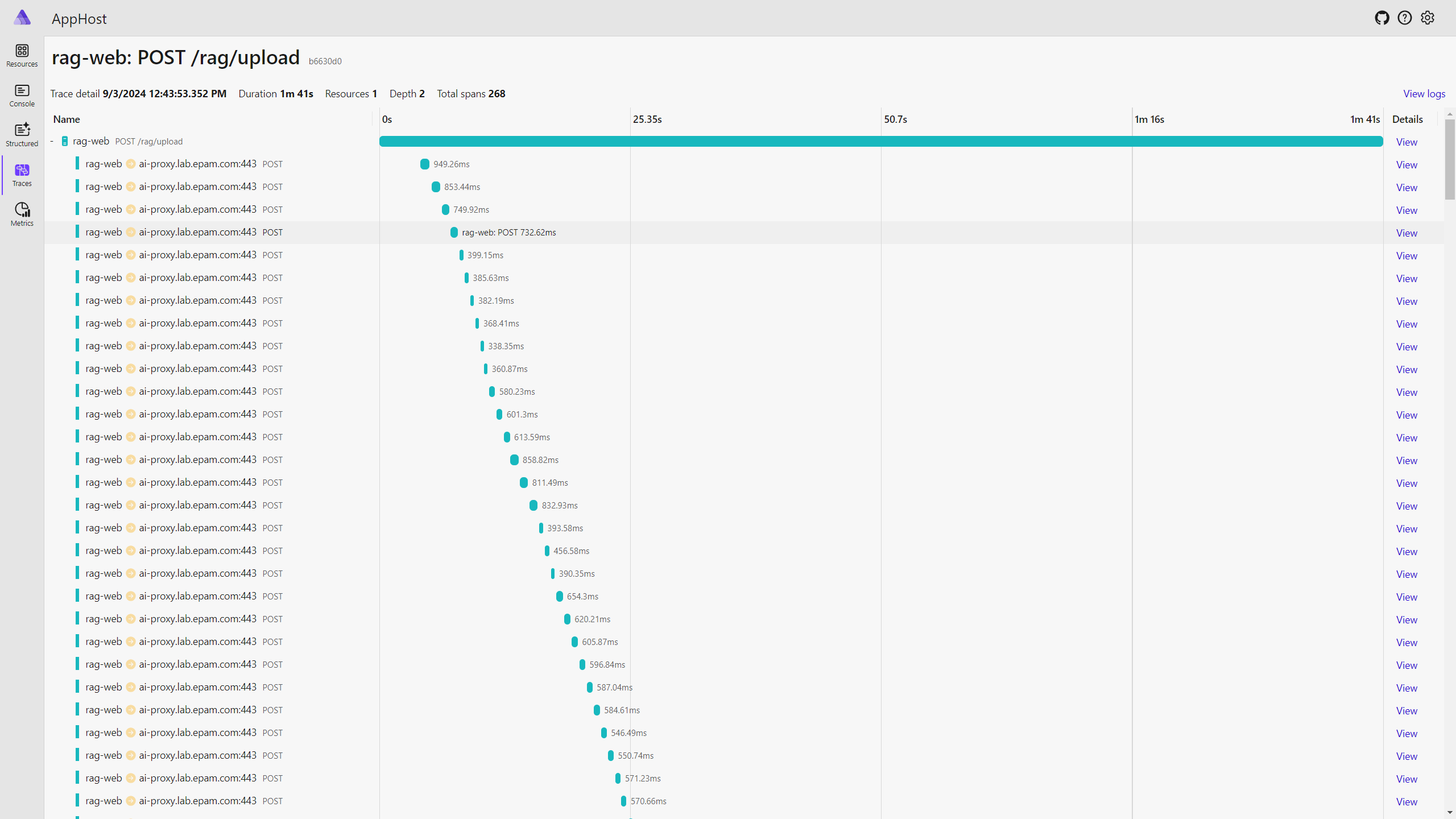
And about 133 partitions/embeddings were created for a single document (8 MB/500 pages).
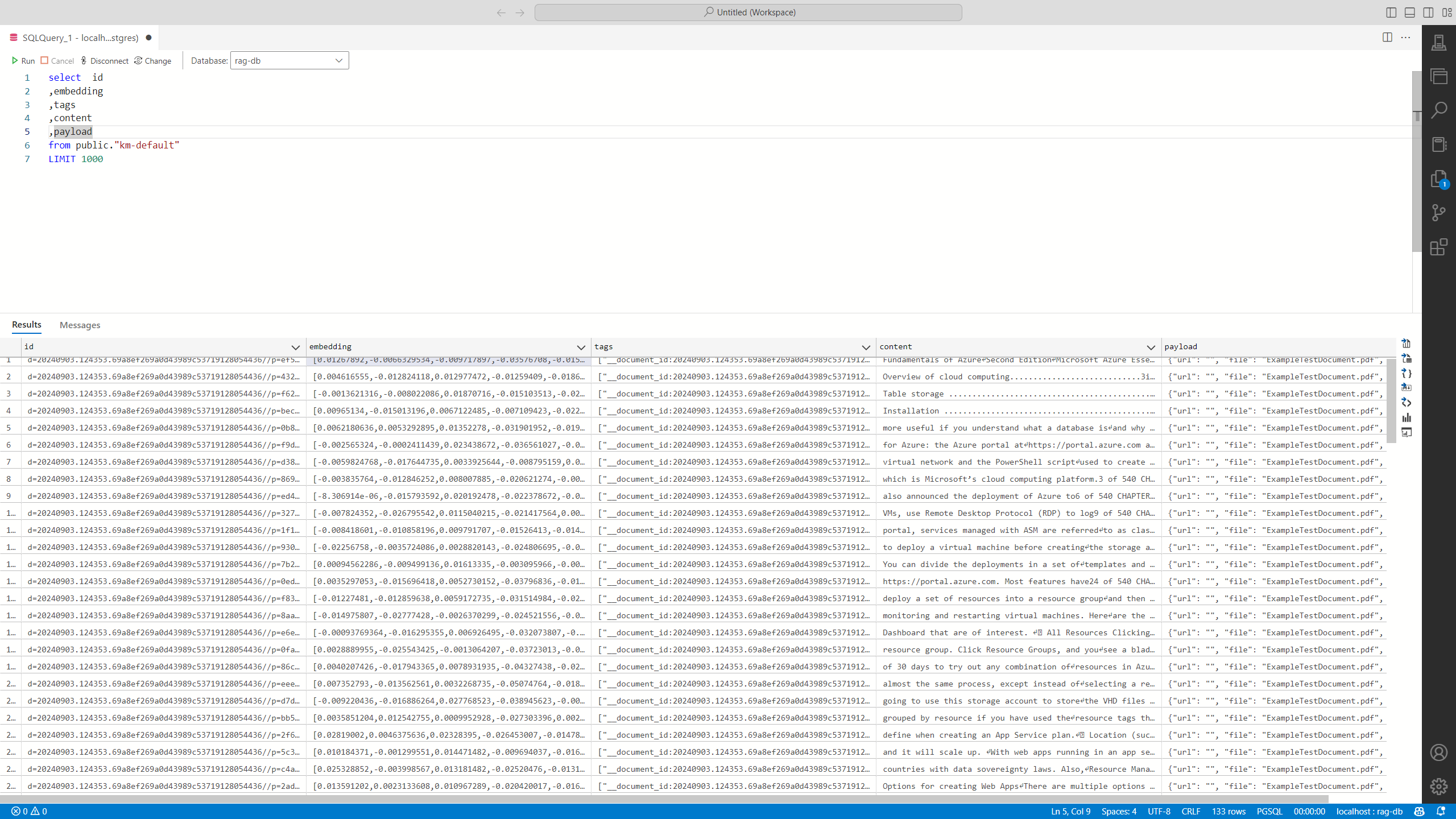
💡Note that the way you chunk your data is important and can impact the way RAG works. For example, you may want to make your chunks bigger and apply summarization to get more abstract answers.
Ask a Question
curl -X 'POST' \
'https://localhost:7016/rag/ask' \
-H 'accept: application/json' \
-H 'content-type: application/json' \
-d '{ "question": "What kind of Azure Database services can I use?" }'
Response:
{
"question": "What kind of Azure Database services can I use?",
"noResult": false,
"text": "Azure offers a variety of database services to cater to different needs, including both SQL and NoSQL options:\n\n1. **Azure SQL Database**: This is a fully managed relational database with built-in intelligence that supports self-driving features such as performance tuning and threat alerts. Azure SQL Database is highly scalable and compatible with the SQL Server programming model.\n\n2. **SQL Server on Azure Virtual Machines**: This service allows you to run SQL Server inside a fully managed virtual machine in the cloud. It is suitable for applications that require a high level of control over the database server and compatibility with SQL Server data management and business intelligence capabilities.\n\n3. **Azure Cosmos DB**: Formerly known as DocumentDB, Azure Cosmos DB is a globally distributed, multi-model database service. It is designed to provide low-latency, scalable, and highly available access to your data, suitable for any scale of business application.\n\n4. **Azure Database for MySQL**: This is a managed service that enables you to run, manage, and scale highly available MySQL databases in the cloud. Using Azure Database for MySQL provides capabilities such as high availability, security, and recovery built into the service.\n\n5. **Azure Database for PostgreSQL**: Similar to Azure Database for MySQL, this service provides a fully managed, scalable PostgreSQL database service with high availability and security features.\n\n6. **Azure Table Storage**: A service that stores large amounts of structured NoSQL data in the cloud, providing a key/attribute store with a schema-less design.",
"relevantSources": [
{
"link": "default/20240903.124353.69a8ef269a0d43989c53719128054436/9b7accc78c164db7a2a630ca57e38d8f",
"index": "default",
"documentId": "20240903.124353.69a8ef269a0d43989c53719128054436",
"fileId": "9b7accc78c164db7a2a630ca57e38d8f",
"sourceContentType": "application/pdf",
"sourceName": "ExampleTestDocument.pdf",
"sourceUrl": "/download?index=default&documentId=20240903.124353.69a8ef269a0d43989c53719128054436&filename=ExampleTestDocument.pdf",
"partitions": [
{
"text": "",
"relevance": 0.8672107,
"partitionNumber": 99,
"sectionNumber": 0,
"lastUpdate": "2024-09-03T09:45:34+03:00",
"tags": {
"__document_id": [
"20240903.124353.69a8ef269a0d43989c53719128054436"
],
"__file_type": ["application/pdf"],
"__file_id": ["9b7accc78c164db7a2a630ca57e38d8f"],
"__file_part": ["1999e1ab04a24174bf6d2c79284b04b5"],
"__part_n": ["99"],
"__sect_n": ["0"]
}
}
]
}
]
}
As you can see, the response contains the answer to the question and the relevant sources. The answer is generated by the OpenAI service, and the relevant sources are the partitions that contain the answer.
Observability
The response time is quite high. It took about 14 seconds to get the answer. This is because the OpenAI service is called to generate the answer, and it takes time.
We can use OpenTelemetry to trace the request and see how much time it takes to get the answer.
public static IHostApplicationBuilder ConfigureOpenTelemetry(
this IHostApplicationBuilder builder
)
{
builder.Logging.AddOpenTelemetry(logging =>
{
logging.IncludeFormattedMessage = true;
logging.IncludeScopes = true;
});
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnostics", true);
AppContext.SetSwitch("Microsoft.SemanticKernel.Experimental.GenAI.EnableOTelDiagnosticsSensitive", true);
builder
.Services.AddOpenTelemetry()
.WithMetrics(metrics =>
{
metrics
.AddAspNetCoreInstrumentation()
.AddMeter("Microsoft.SemanticKernel*")
.AddHttpClientInstrumentation()
.AddRuntimeInstrumentation();
})
.WithTracing(tracing =>
{
tracing
.AddAspNetCoreInstrumentation()
.AddSource("Microsoft.SemanticKernel*") // add this to trace Semantic Kernel
.AddHttpClientInstrumentation();
});
builder.AddOpenTelemetryExporters();
return builder;
}
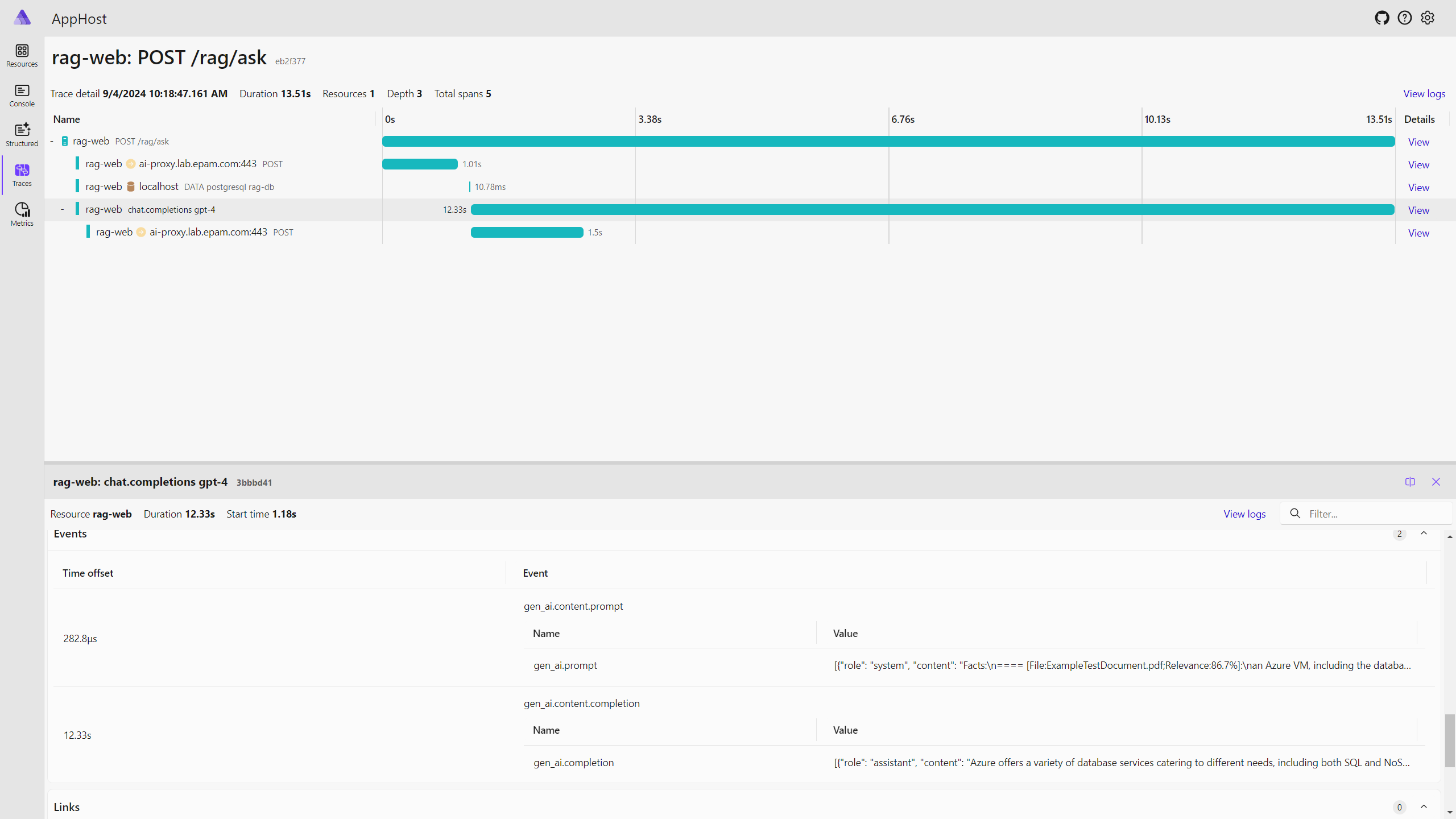
Semantic Kernel instrumentation adds a lot of interesting information that can help you to understand how the interaction with LLM works:
| Key | Value |
|---|---|
| gen_ai.operation.name | chat.completions |
| gen_ai.request.max_tokens | 300 |
| gen_ai.request.model | gpt-4 |
| gen_ai.request.temperature | 0 |
| gen_ai.request.top_p | 0 |
| gen_ai.prompt | ... |
| gen_ai.completion | ... |
Here is an example of gen_ai.prompt and gen_ai.prompt completion.
Prompt:
[
{
"role": "system",
"content": "Facts:\n==== [File:ExampleTestDocument.pdf;Relevance:86.7%](CONTENT_ABBREVAITED)\nQuestion: What kind of Azure Database services can I use?\nAnswer: "
}
]
Completion:
[
{
"role": "assistant",
"content": "Azure offers a variety of database services catering to different needs, including both SQL and NoSQL options:\n\n1. **Azure SQL Database**: This is a fully managed relational database with built-in intelligence that supports self-driving features such as performance tuning and threat alerts. Azure SQL Database is highly scalable and compatible with the SQL Server programming model.\n\n2. **SQL Server on Azure Virtual Machines**: This service allows you to run SQL Server inside a fully managed virtual machine in the cloud. It is suitable for applications that require complete control over the database server and is ideal for migrating existing SQL Server workloads to the cloud.\n\n3. **MySQL Database**: Azure facilitates MySQL as a managed service, which is easy to set up, manage, and scale. This service is provided through a partnership with SuccessBricks\u2019 ClearDb, offering a fully managed MySQL database.\n\n4. **Azure Database for PostgreSQL**: This is a managed service that makes it easier to set up, manage, and scale PostgreSQL databases in the cloud.\n\n5. **Azure Cosmos DB**: Formerly known as DocumentDB, Cosmos DB is a globally distributed, multi-model database service that supports schema-less data, which makes it a suitable option for web, mobile, gaming, and IoT applications.\n\n6. **Azure Table Storage**: This service offers highly available, massively scalable storage, which is ideal for applications requiring a flexible NoSQL key-value store.\n\n7. **Azure MongoDB**: Through the Azure Marketplace, MongoDB can be hosted on Azure Virtual Machines, providing"
}
]
Conclusion
In this article, we have seen how to build a typical RAG solution using Semantic Kernel, Kernel Memory, and Aspire in .NET. We have also seen how to add OpenTelemetry instrumentation to trace the request and see how long it takes to get the answer. I hope you find this article helpful. 🙌
References
- https://learn.microsoft.com/en-us/semantic-kernel/get-started/quick-start-guide?pivots=programming-language-csharp - Semantic Kernel Quick Start Guide
- https://microsoft.github.io/kernel-memory - Kernel Memory Docs
- https://github.com/microsoft/semantic-kernel/blob/main/dotnet/docs/TELEMETRY.md - OpenTelemetry + Semantic Kernel
- dotnet (59) ,
- semantic-kernel (2) ,
- kernel-memory (2) ,
- opentelemetry (4) ,
- ai (9) ,
- aspire (18) ,
- rag (2)
